To eBGP or not to iBGP — that is the query (please 🐻 with me ;)
BGP EVPN with VXLAN to the multi-tenant hosts (using SR Linux and SR OS)

There are many ways to do things, and some ways are subjectively better than others. Sometimes, things that may have been a Bad Idea™ in the past become a Not_So_Bad_After_All(maybe, provided X and not Y) option in light of new developments or concerns. To tell which one is which, we’ll just have to give it a go and see where we end up. And whatever happens — 🤞 chances are we’ll learn some things in the process regardless!
The evolution of BGP-to-the-host (how the … did we end up here?)

“Accelerating waves of change to open (2021)” paints a picture of how we can see things evolving over time. From hardware to software, from L2 to static L3 to dynamically signaled L3 with BGP to VXLAN (L2-over-L3) — it all follows a similar pattern of evolutionary change, building on technology from the past to create the future, following the path of the adjacent possible. The terminology and acronyms we humans like to use may vary over time, but the underlying principles and nature of the problems being solved remain much the same.
Which brings us back to BGP
(i/e)BGP: The Bearable Gentle Protocol 🔨
With BGP being the foundation of the internet, it should not surprise you that 179 is a prime number. It is the TCP port for the primary protocol, by design — and to those who would submit that 89 (OSPF IP protocol number) is prime too, I would ask why anyone would consider that relevant. I mean, come on! Really?
I’m joking of course, but wars have been fought over less and I wanted to make it very clear that I am not aiming to start another one here. It so happens that EVPN requires BGP (with the EVPN protocol family), so the only technical question that still remains, is if it will be iBGP, or eBGP, or — dare I say it — both?
EVPN with iBGP: A single AS for auto-derived Route Targets
In my Nuage days, we used to do iBGP sessions for the EVPN overlay (like this for example). As described in RFC8635, auto-derivation of RTs is based on a common 2-byte Autonomous System; with iBGP peering you have that auto-covered.
However, unbeknownst to me at the time and until very recently, there are ongoing (heated) arguments within the networking community about the merits and issues associated with doing iBGP-over-eBGP. I don’t know if those discussions ever included BGP extended to hosts, but if you believe iBGP-over-eBGP between spines and leaves is bad enough, I’d guess iBGP-over-eBGP-with-hosts must be worse?
EVPN with eBGP and local AS: The best of both worlds?
We still need a single AS for auto-derived RTs, but how about we use “local AS” on interfaces and implement eBGP peering only, with both IPv4 and EVPN address families? Provided we can keep the leaves from modifying the next hop received from other VXLAN endpoints, that should appease the crowd? iBGP without actual iBGP peering sessions 🤔
If a tree falls in a forest and no one is around to hear it, does it make a sound? (if we assign the same AS to every node but use local-as for every peer, is it still iBGP?)
“System supports any type of BGP for EVPN, as long as it’s iBGP”
Or as at least one vendor puts it, “A supported configuration/design with eBGP is eBGP with local-as override on the session to an iBGP RR”. To my ears, a BGP session with local-as set to the same value as the iBGP Route Reflector AS sounds an awful lot like iBGP, but who am I to argue with a product document?
Between 0x2 nerds on the use of eBGP (not iBGP) in data centers
In 2020 Jeff and Jeff did a vodcast about eBGP in the data center, based on RFC7938. They paint iBGP as a kind of watered down eBGP, without loop detection.
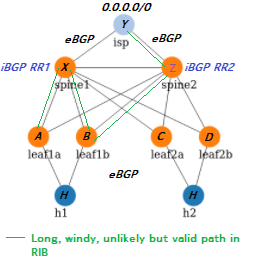
The thing is: If we were to use eBGP for both the underlay (ipv4/v6) and also for EVPN overlay routes, then we may gain loop detection (based on AS path) but it would come at the expense of hop-by-hop trickle exchanges of EVPN route changes. And in a centralized iBGP Route Reflector topology with all iBGP speakers connecting to a central pair of RRs (e.g. at the spines), what is the risk of routing loops? RFC4456 adds 2 attributes to perform (some form of) loop detection in iBGP route reflection situations, the originator_id (set to the sending router) and the cluster_id (acting like a kind of AS path), so loop detection is pretty similar (if not equivalent). There is no risk of iBGP EVPN routes getting sent to eBGP peers, because of the different address family, and there are no valleys in a centralized star topology.
The talk mentions the possibility of extending BGP to the hosts, but does not go into the details of AS allocation for those BGP speakers — could they use the same AS?
There is a kind of “natural filtering” happening through the use of AS-path in eBGP, eliminating unrealistically long paths, and it would certainly be useful to filter EVPN routes such that — for example — a given host only receives EVPN routes related to subnets it has VMs running on (as opposed to all routes for the entire data center). However, given that VMs can be moved around arbitrarily, the AS structure of the underlay is not usable in this context.
Design time
Long story short: Let’s try the following design:
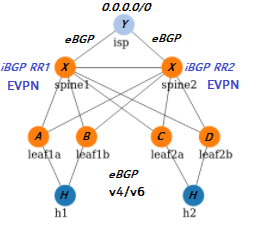
- eBGP for the underlay, with a default route originating from the ISP and propagated down to each Linux host (ECMP to a pair of leaves). That way, if both uplinks for a leaf should fail, the default route is withdrawn and the Linux hosts failover to the other leaf.
- Single loopback route exported by every Linux host via eBGP, to each leaf
- Same eBGP AS for each Linux host (to keep the configuration simple and invalidate paths via hosts) and each spine (to filter routes that pass multiple spines and get valley-free zigzag-less routing, see diagram below). Note that the Linux hosts can only use the same AS in combination with receiving a default route, they would reject any specific loopback routes from/to other Linux hosts (due to the AS already being in the path)
- multi-hop iBGP between loopbacks for the EVPN overlay, to a pair of route reflectors (co-located on the SR OS spines here; could be running anywhere). Investigate whether RT Constraint or other filtering techniques could be used to reduce the amount of EVPN routes sent to each host.
Here you can find a Github project with the details, including pending PRs required to implement all the configs.
VXLAN+EVPN to the hosts, with selective North-South L3 break-out to the internet
Having sorted out the control plane, it is now time to face the data plane. An important design consideration is the ratio between east-west traffic (between servers) and north-south traffic (to the outside, for example internet); trends from the past have included dramatic growth in east-west (e.g. due to multi-tiered and/or micro-service application architectures), while some data centers are experiencing increased north-south traffic due to rising public cloud usage.
Whatever the traffic mix, any packet that can be processed on the host is one less to be handled by the network. Both L2 and L3 traffic between VMs or containers is ideally forwarded in server software (for better latency, reliability and capacity), leaving only L3 North-South traffic to be handled in the (border) leaves and/or (gateway) spines.
Given multi-tenancy requirements, we can assume that tenants are separated into different Virtual Routing Function(VRF) contexts, with isolated address spaces.
L3 VXLAN hand-off options: L2 or L3 VNI
The IETF defines 2 VXLAN routing models in RFC9135:
- Symmetric IRB (with separate L3VNI per VRF)
- Asymmetric IRB (using only target L2VNIs)
“Symmetric IRB” makes use of additional so-called L3VNIs and performs a route lookup at both source and destination VTEP, whereas “Asymmetric IRB” uses the destination L2VNI and only performs a route lookup at the source.
For the specific use case of L3 break-out of north-south traffic, this has the following implications:
Symmetric IRB L3 hand-off: Single shared internet L3VNI
In the symmetric case, a shared “internet L3VNI” can be used by all tenants to route traffic from any L2 subnet. Given that traffic will be sent out over the same shared network, mixing the traffic early like this should not be an issue (unless per-tenant security policies would need to be applied).
It is mentioned FRR supports this model with “EVPN external routing”; if not, a per-tenant VRF with associated VNI would have to be instantiated on each gateway, with inter-VRF leaking to a common internet VRF.
Asymmetric IRB L3 hand-off: L2 MAC-vrf for every subnet
In a purely asymmetrical IRB design, L3VNIs don’t exist. Therefore, the gateway VTEP router would need to be provisioned with every L2VNI for which external routing is required (joined into a shared internet VRF). This model has the advantage that internet access can be allowed or denied simply by provisioning or not provisioning the corresponding L2VNI on the gateway. The downside is that every (dynamic) subnet that needs internet access requires a corresponding MAC-vrf on every gateway.
On the FRR Linux host side, this model seems easier to implement as it makes the gateway look just like any another VTEP. One could implement a dedicated “Internet transit” L2 subnet (say 192.0.0.0/31) per tenant VRF, and put a static default route to the gateway for internet access.
To be continued
I realize there is more to be said and thought through, designing next generation data center fabrics clearly doesn’t happen over night or in the span of a single blog post. I welcome your comments and (constructive) feedback based on your own experience — am I really crazy to consider iBGP-over-eBGP?
Until we virtually meet again 👋
